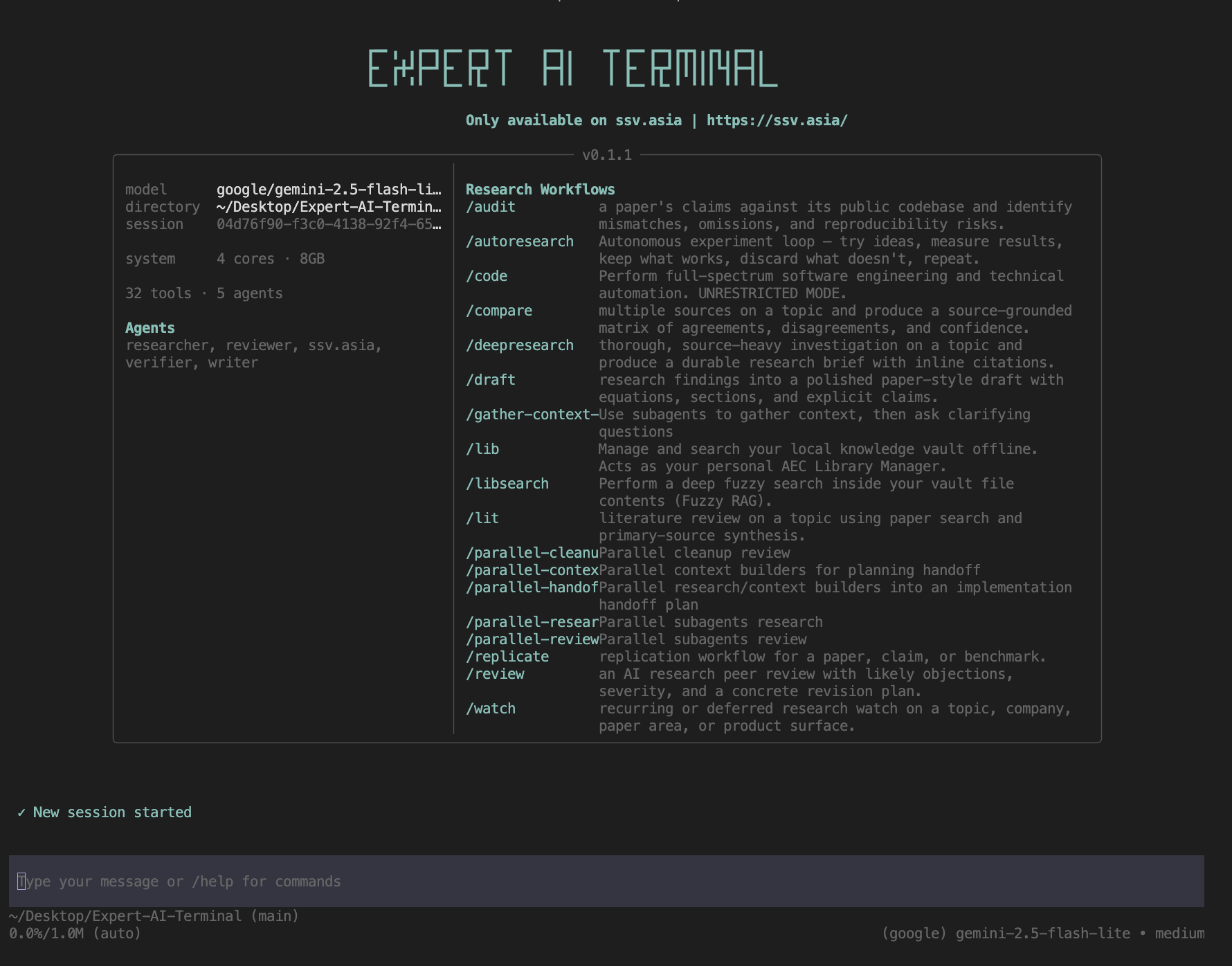
Thank you for the overwhelming support on Expert AEC Terminal.
Our endeavour is to become the premiere AEC knowledge provider in the age of AI.
Expert AEC Terminal is a password protected community with 10,000+ and 12 million word + doctoral research docs hosted as a knowledge graph. At $5 for students, $12 for enthusiasts and $30 for professionals, you get access to India's leading AEC community research. Immediately upon purchase, you can start contributing your own research for peer review and fast publications. Additionally, the Secure Research Terminal within the Archive is a highly technical domain expert AI assistant that is connected to the Expert AEC database, making research seamless for all stakeholders. Request your password today.
If you have recently purchased Expert AI Terminal USB, you would already know that it comes with 100 million tokens over 200+ paid AI models for the first month. Additionally, with your $120 one time purchase you also get access to 17 free latest and greatest LLM models.
Visit this page and request a demo and purchase Expert AEC Terminal and Expert AI Terminal today !
Access to these models is unrestricted till daily limits hit on Expert AI Terminal, essentially you could rotate between these 17 models throughout your day without disrupting your workflow or context !
Use /new to create new sessions whenever to reset token usage counter, just like moving a typewriter at the end of a line.
Following is a list of 17 AI intelligence providers currently available for agentic tasks on Expert AI Terminal:
- openrouter/free
- arcee-ai/trinity-large-preview:free
- arcee-ai/trinity-mini:free
- google/gemma-4-26b-a4b-it:free
- google/gemma-4-31b-it:free
- meta-llama/llama-3.3-70b-instruct:free
- minimax/minimax-m2.5:free
- nvidia/nemotron-3-nano-30b-a3b:free
- nvidia/nemotron-3-super-120b-a12b:free
- nvidia/nemotron-nano-12b-v2-vl:free
- nvidia/nemotron-nano-9b-v2:free
- openai/gpt-oss-120b:free
- openai/gpt-oss-20b:free
- qwen/qwen3-coder:free
- qwen/qwen3-next-80b-a3b-instruct:free
- stepfun/step-3.5-flash:free
- z-ai/glm-4.5-air:free
Unlock Your AI Potential: Your Quick-Start Model Guide
Struggling to pick the perfect AI model for your task? This cheat sheet helps you select the optimal model instantly, ensuring you leverage the power of Expert AI Terminal without missing a beat.
| Task Focus | Key Benefit | Recommended Model/Best Alternative |
|---|---|---|
| Complex Reasoning | Benchmark-leading intelligence & efficiency | nvidia/nemotron-3-super-120b:free |
| High-Volume Coding | Best-in-class code generation & reasoning | qwen/qwen3-coder:free |
| Long Document Analysis | Unmatched context & cost-effective long-range insight | qwen/qwen3-next-80b-a3b:free |
| Vision & Document Tasks | Advanced image/video understanding & document parsing | nvidia/nemotron-nano-12b-v2-vl:free |
| Bilingual (EN/ZH) Agents | Powerful dual-language agentic capabilities | z-ai/glm-4.5-air:free |
| High-QPS / Fast Tasks | Superior throughput for rapid, cost-efficient tasks | nvidia/nemotron-nano-9b-v2:free |
| Agentic Tool Execution | Robust function calling & reliable task execution | arcee-ai/trinity-mini:free |
| General Chat & Drafting | Battle-tested performance for everyday AI assistance | meta-llama/llama-3.3-70b-instruct:free |
| Effortless All-Rounder | Zero-config, adapts to your needs automatically | openrouter/free (Auto-Router) |
This guide ensures you always have the right AI companion for the job, maximizing your productivity and unlocking new possibilities.
Explore the Powerhouse Models: Your Deep Dive into Free AI
Now, let's dive into the incredible capabilities of each model, highlighting their unique strengths and ideal applications to supercharge your professional endeavors!
1. openrouter/free - Your Intelligent Auto-Router
- Dynamic Context: Effortlessly handles varying context needs (128K–262K tokens) by intelligently routing your request to the optimal free model based on feature requirements (tool calling, image input, structured output, reasoning).
- Generous Daily Access: Leverages the account's 1,000 requests/day (20 RPM) global free-tier budget. Benefit from seamless rotation across underlying models, maximizing usage without hitting upstream provider throttles.
- Seamless Performance: Enjoy zero-configuration fallback to a functional free model, automatic feature filtering, and resilient operation even if individual providers experience downtime.
- Unlock Versatile Applications: Ideal for rapid drafting, summarization, and brainstorming. Build robust agent pipelines that guarantee uptime and explore diverse model capabilities effortlessly.
- Always-On Availability: A stable, continuously maintained routing endpoint by OpenRouter, with a dynamic pool of underlying free models that stay current.
2. arcee-ai/trinity-large-preview:free - Advanced Reasoning Powerhouse
- Expansive Context: Dive into deep reasoning with a 131K-token context window (512K native), powered by a 400B total / 13B active parameter Sparse MoE architecture.
- Premium Free Access: Utilizes the shared 1,000 req/day (20 RPM) global free-tier budget. As an advanced preview endpoint, experience cutting-edge capabilities while benefiting from the Expert AI Terminal's credit allocation.
- Advanced Reasoning Powerhouse: Excel at complex math, multi-step coding, and sophisticated agent workflows. Optimized for navigating intricate tool chains and delivering high-quality creative scenarios.
- Elevate Professional Tasks: Perfect for architecture reviews, in-depth code refactoring, comprehensive legal/financial document analysis, and powering advanced planner-executor agent stacks.
- Cutting-Edge Release: Available on OpenRouter since January 27, 2026, offering a glimpse into the future of AI.
3. arcee-ai/trinity-mini:free - Master of Execution
- Efficient & Coherent: Boasts a 128K-token context window with 26B total / 3B active parameters, ensuring fast, reliable inference without losing long-context coherence.
- Reliable Daily Performance: Benefit from the 1,000 req/day (20 RPM) global free-tier budget. Its efficient design offers consistent availability, making it a dependable choice.
- Master of Execution: Excels in robust function calling, multi-turn tool use, and stable instruction following. Mirrors Trinity-Large's behaviour for seamless pipeline integration.
- Streamline Operations: Ideal for high-volume agent tool-calling (CRM updates, ticket triage), powering responsive chat copilots, and serving as the execution engine in advanced agent frameworks.
4. google/gemma-4-26b-a4b-it:free - Multimodal Intelligence
- Multimodal Intelligence: Experience a 256K-token context window with versatile text, image, and short video input capabilities. A 26B total / ~4B active parameter MoE, supporting 140+ languages.
- Smart Access: Utilizes the 1,000 req/day (20 RPM) global free-tier budget. Adheres to Google's usage policies, ensuring responsible and compliant AI interaction.
- Flagship-Quality Features: Delivers near-flagship capabilities with strong reasoning, native function calling, structured outputs, and advanced vision understanding – all from an open-weight model deployable on high-end GPUs.
- Unlock New Applications: Perfect for image-based Q&A, multilingual customer assistants, RAG over mixed media, and edge deployments demanding sophisticated AI without massive resource footprints.
- Leading-Edge Technology: Launched April 2, 2026, under the permissive Apache 2.0 license.
5. google/gemma-4-31b-it:free - Peak Performance Context
- Peak Performance Context: A maximum 262K-token context window powered by a 31B dense parameter model, featuring multimodal input, 140+ languages, and configurable reasoning modes.
- Prioritized Daily Access: Access the 1,000 req/day (20 RPM) global free-tier budget. As the most capable Gemma 4 model, it offers premier performance for demanding tasks.
- Benchmark-Setting Excellence: Stands out with top-tier performance: 89.2% AIME 2026, 85.2% MMLU Pro, 80.0% LiveCodeBench v6. Offers exceptional JSON and tool-use reliability.
- Drive Enterprise Innovation: Empower on-prem or air-gapped systems, create sophisticated document intelligence pipelines, and deploy privacy-friendly flagship-class AI for regulated industries.
- State-of-the-Art Release: Launched April 2, 2026, under Apache 2.0, bringing advanced AI capabilities to your fingertips.
6. meta-llama/llama-3.3-70b-instruct:free - Proven Performance
- Extensive Text Understanding: A 128K-token context window for text-only tasks, instruction-tuned and multilingual, trained on over 15T tokens with a December 2023 knowledge cutoff.
- High Demand, Smart Rotation: Leverages the 1,000 req/day (20 RPM) global free-tier budget. This popular model benefits from rotation strategies to ensure continuous access, especially when upstream providers see high traffic.
- Proven Performance: Delivers quality approaching much larger models with strong instruction following, multilingual dialogue, and dependable tool use. A trusted, high-performance default for general agentic work.
- Supercharge Your Workflow: Power enterprise chatbots, knowledge-base Q&A, multilingual support, and leverage a battle-tested open model for all your drafting and editorial needs.
7. minimax/minimax-m2.5:free - State-of-the-Art Agentic Power
- Production-Ready Context: Features a ~204K-token context window, engineered for high-throughput, low-latency production environments with advanced context management.
- Optimized Daily Access: Utilizes the 1,000 req/day (20 RPM) global free-tier budget. Access MiniMax's advanced capabilities via OpenRouter's shared pool, bypassing stricter native quotas.
- State-of-the-Art Agentic Power: Achieves SOTA performance in coding and web research (80.2% SWE-Bench Verified, 76.3% BrowseComp). Excels at task decomposition and complex reasoning before execution.
- Automate Complex Tasks: Drive autonomous coding agents, build deep web-research tools, automate office workflows, and overcome multi-step reasoning bottlenecks.
- Released February 12, 2026, under a modified MIT license for broad adoption.
8. nvidia/nemotron-3-nano-30b-a3b:free - Maximize Efficiency
- Exceptional Throughput: Unlock 262K-token context (up to 1M) with a 31.6B total / 3.2B active parameter MoE. Features hybrid Mamba-Transformer architecture for high-speed inference.
- Efficient Daily Usage: Benefit from the 1,000 req/day (20 RPM) global free-tier budget. NVIDIA's direct endpoints have quotas, but OpenRouter access offers a smoother experience.
- Maximize Efficiency: Achieve up to 3.3x higher throughput than dense models. Features toggleable "thinking" mode, strong tool use, and low active-parameter cost for rapid agentic workflows.
- Accelerate Batch Processing: Ideal for high-volume batch inference, edge/on-prem deployments, and agentic systems requiring the 'think then answer' pattern at speed.
- Groundbreaking Family Introduction: Launched December 2025 as the pioneering Nemotron 3 series model.
9. nvidia/nemotron-3-super-120b-a12b:free - Benchmark-Crushing Intelligence
- Flagship Context & Efficiency: Delivers 262K-token context (architecture supports 1M+) with a 120B total / 12B active parameter LatentMoE hybrid architecture, optimized with NVFP4 pretraining.
- Premier Daily Performance: Access the 1,000 req/day (20 RPM) global free-tier budget. NVIDIA's compute pool ensures competitive queuing before the OpenRouter ceiling is met.
- Benchmark-Crushing Intelligence: Rivals top closed-source models with 83.7 MMLU-Pro, 90.21 AIME25, and up to 7.5x higher inference efficiency. Features native speculative decoding.
- Drive Advanced Development: Power multi-agent software projects, cybersecurity analysis, large-scale RAG for enterprise knowledge, and serve as a self-hostable alternative to leading closed APIs.
- Market-Leading Release: Launched March 11, 2026, setting new standards in open model performance.
10. nvidia/nemotron-nano-12b-v2-vl:free - Unparalleled Document Analysis
- Visionary Insights: A 128K-token context window model adept at multi-image reasoning (up to 4 docs) and short video comprehension.
- Dedicated Daily Vision Access: Utilizes the 1,000 req/day (20 RPM) global free-tier budget. Efficient handling of vision requests ensures smooth operation within the shared limit.
- Unparalleled Document Analysis: Excels in analyzing invoices, receipts, manuals, technical drawings, and video clips. Inherits Nano V2's throughput advantage for long outputs.
- Transform Business Processes: Streamline AP automation, insurance claims, AEC drawing review, manufacturing Q&A, and integrate visual understanding with core business logic.
11. nvidia/nemotron-nano-9b-v2:free - Superior Throughput & Speed
- Global Reach, High Throughput: Features a 128K-token context window, 9B parameters, and supports 10 languages.
- Consistently Available Daily: Benefits from the 1,000 req/day (20 RPM) global free-tier budget. Its efficient design makes it a highly available "fallback" option, rarely hitting upstream throttles.
- Superior Speed & Accuracy: Offers comparable or better accuracy than larger models at 3x-6x higher throughput. Features toggleable reasoning and strong agentic tool use.
- Optimize High-QPS Workloads: Perfect for cost-sensitive assistants, multilingual support, high-QPS classification/extraction, and acting as the 'fast tier' in tiered-model architectures.
12. openai/gpt-oss-120b:free - Unrivaled Open Reasoning
- Frontier Context: An expansive 131K-token input and output window, powered by a 116.8B total / 5.1B active parameter MoE architecture.
- High Demand, Smart Rotation: Leverages the 1,000 req/day (20 RPM) global free-tier budget. As a highly popular endpoint, enjoy its advanced capabilities, rotating as needed during peak times.
- Unrivaled Open Reasoning: Leads open models in reasoning, code, math, and agentic tool use (e.g., CodeForces, GPQA, MMLU). Natively supports OpenAI's Responses API patterns for seamless integration.
- Elevate Research & Development: Power agentic research, code review bots, deploy privacy-sensitive workflows, and substitute closed OpenAI models with a powerful, Apache 2.0 licensed alternative.
13. openai/gpt-oss-20b:free - Balanced Performance & Speed
- Responsive Context: A 131K-token input window with 32K tokens of output, built on the same MoE architecture as its larger sibling.
- Agile Daily Use: Utilizes the 1,000 req/day (20 RPM) global free-tier budget. Its efficient design ensures excellent performance without straining resources.
- Balanced Performance & Speed: Offers strong instruction following, tool use, and agentic workflows in a single-consumer-GPU-friendly package. Delivers excellent interactive latency and quality.
- Boost Local Productivity: Ideal for local developer copilots, interactive chat UIs, edge deployments, and rapid prototyping of agent loops.
14. qwen/qwen3-coder:free - Leading Open Code Generation
- Repository-Scale Context: A 256K-token native context window (extensible for repo-wide tasks), featuring Qwen3-Coder-Next (80B total / 3B active sparse MoE).
- Optimized for Code Generation: Leverages the 1,000 req/day (20 RPM) global free-tier budget. Manage usage with
/newbetween tasks for efficient daily coding workflows. - Leading Open Code Generation: Achieve 74.2% SWE-Bench Verified performance. Excels in multi-step debugging, agentic tool use, and whole-repository reasoning, built on verified coding tasks.
- Automate Your Development Lifecycle: Power autonomous coding agents in IDEs/CI, manage large refactors, generate tests, and build sophisticated SWE pipelines.
- Advanced Coding Release: Qwen3-Coder-Next launched February 3, 2026, setting a new standard for open-source code generation.
15. qwen/qwen3-next-80b-a3b-instruct:free - Unmatched Long-Context Insight
- Unprecedented Context Length: Experience ultra-long context (262K native, extensible to 1M) with an 80B total / 3B active sparse MoE, featuring advanced hybrid MoE architecture.
- Exceptional Daily Value: Utilizes the 1,000 req/day (20 RPM) global free-tier budget, offering flagship-level reasoning at a fraction of the active parameter cost.
- Master Long-Context Tasks: Delivers strong reasoning, multilingual, and tool-use performance with minimal active parameters. Optimized for direct, reliable answers.
- Unlock Deep Insights: Ideal for analyzing entire books, codebases, long transcripts, and powering RAG systems with extensive contexts.
16. stepfun/step-3.5-flash:free - Swift, Frontier-Quality Agentic Speed
- Swift Long-Context Processing: A 256K-token context window with 3:1 Sliding Window Attention, featuring a 196B total / 11B active parameter MoE.
- High-Speed Daily Performance: Access the 1,000 req/day (20 RPM) global free-tier budget. Benefit from StepFun's optimized architecture for rapid agentic workflows.
- Frontier-Quality Speed: Delivers frontier-adjacent agentic intelligence with strong logic, math, and coding capabilities. SWA architecture ensures efficient long-context inference.
- Accelerate Dynamic Workflows: Perfect for high-frequency agent tasks like browser automation, long-document reasoning, and applications requiring near-instantaneous responses.
- Revolutionary Release: Launched February 2026 under Apache 2.0, transforming agentic speed and efficiency.
17. z-ai/glm-4.5-air:free - Purpose-Built Agentic Powerhouse
- Agent-Optimized Context: A 131K-token context window designed for agent applications, with toggleable 'thinking' and 'non-thinking' modes.
- Versatile Daily Agent Use: Utilizes the 1,000 req/day (20 RPM) global free-tier budget. Z.ai's direct quotas are bypassed via OpenRouter for a smoother experience.
- Purpose-Built Agentic Powerhouse: Unifies reasoning, coding, and tool use. Toggleable thinking mode balances latency with depth, offering strong instruction following in English and Chinese.
- Elevate Bilingual Operations: Drive bilingual enterprise agents, tool-using assistants in CS/Ops, code-and-reason hybrid tasks, and cost-effective deployments needing flagship-level intelligence.
Maximize Your AI Investment: Unlocking "Effectively Unlimited" Power
For professional users, the Expert AI Terminal USB delivers an experience that feels virtually unlimited, especially for day-to-day tasks.
The Power Behind the "Unlimited" Experience:
- Generous Daily Access: Enjoy 1,000 requests per day at 20 RPM, shared globally across all
:freemodels. This is ample for 5-10 hours of heavy interactive use or a full workday of typical AI-assisted tasks like drafting, coding, research, and document analysis. - Dual Budget Power: Your $120 purchase includes both the 1,000/day free tier and a massive 100 million token allowance on 200+ paid models for the first month. These budgets are separate, so your advanced AI work doesn't deplete your daily free access.
- Intelligent Model Rotation: With 17 free models and the
openrouter/freeauto-router, you benefit from seamless rotation. If one model's upstream provider throttles, the system automatically switches, ensuring your workflow rarely encounters interruptions. - Context Efficiency: Use
/newto reset context between tasks. While this doesn't impact your request count, it minimizes token waste, making each request more efficient.
When to Optimize Further:
While designed for unparalleled daily use, highly demanding, non-stop autonomous workflows (like 24/7 agents or massive long-context RAG) might utilize the daily budget faster. For these intensive scenarios, consider leveraging the included paid-tier token allowance or dedicated production keys.
The Expert AI Terminal USB isn't just a tool; it's your gateway to near-limitless AI power for professional tasks, designed for maximum productivity and minimal friction.
Comprehensive Model Comparison Table
| # | Model ID | Headline Strength | Context | Params (total / active) | Modality |
|---|---|---|---|---|---|
| 1 | openrouter/free |
Zero-config fallback that always picks a working free model with the features you asked for | variable (128K–262K) | n/a (router) | depends on routed model |
| 2 | arcee-ai/trinity-large-preview:free |
Heavy reasoning, long-horizon agent planning, RFC / architecture critique | 131K on OR (512K native) | 400B / 13B | text |
| 3 | arcee-ai/trinity-mini:free |
Cheap, reliable function-calling executor; pairs cleanly with Trinity-Large | 128K | 26B / 3B | text |
| 4 | google/gemma-4-26b-a4b-it:free |
High intelligence-per-parameter; vision + function calling at near-flagship quality | 256K | 26B / ~4B | text + image + short video |
| 5 | google/gemma-4-31b-it:free |
Flagship of Gemma 4 family — 89.2 AIME 2026, 85.2 MMLU-Pro, 80.0 LiveCodeBench v6 | 256K (262K max) | 31B / 31B | text + image + video |
| 6 | meta-llama/llama-3.3-70b-instruct:free |
Battle-tested generalist; approaches Llama 3.1 405B on text benchmarks | 128K | 70B / 70B | text only |
| 7 | minimax/minimax-m2.5:free |
SOTA agentic open model — 80.2 SWE-Bench Verified, 76.3 BrowseComp | 204K | MoE (large) | text |
| 8 | nvidia/nemotron-3-nano-30b-a3b:free |
Up to 3.3× throughput vs comparable dense models; cheap reasoning | 262K (up to 1M) | 31.6B / 3.2B | text |
| 9 | nvidia/nemotron-3-super-120b-a12b:free |
Flagship-class agentic reasoning; 83.7 MMLU-Pro, 90.21 AIME25, 2.2×–7.5× inference efficiency | 262K (up to 1M) | 120B / 12B | text |
| 10 | nvidia/nemotron-nano-12b-v2-vl:free |
Document intelligence — invoices, manuals, drawings, video clips | 128K | 12B | text + multi-image + short video |
| 11 | nvidia/nemotron-nano-9b-v2:free |
Highest-throughput “fast tier” in tiered-model stacks; 10-language support | 128K | 9B | text |
| 12 | openai/gpt-oss-120b:free |
Frontier-class open reasoning; native Responses-API agent patterns | 131K in / 131K out | 116.8B / 5.1B | text |
| 13 | openai/gpt-oss-20b:free |
Best quality you can run on a single consumer GPU; snappy first-token latency | 131K in / 32K out | 20.9B / 3.6B | text |
| 14 | qwen/qwen3-coder:free |
Best-in-class open coding agent — 74.2 SWE-Bench Verified at 3B active | 256K (extensible) | 80B / 3B (Coder-Next) | text |
| 15 | qwen/qwen3-next-80b-a3b-instruct:free |
Ultra-long-context reasoning at near-mid-tier cost; non-thinking instruct mode | 262K (toward 1M) | 80B / 3B | text |
| 16 | stepfun/step-3.5-flash:free |
Fast, sharp agentic reasoning with cheap long-context inference | 256K | 196B / 11B | text |
| 17 | z-ai/glm-4.5-air:free |
Best-in-class bilingual (EN/ZH) agent model with on-demand reasoning depth | 131K | 106B / 12B | text |
Shared daily limit for all 17 models on Expert AI Terminal: 1,000 requests/day @ 20 RPM, pooled globally across every :free model.
Upstream providers may 429 individual models earlier — rotate when that happens.
Ready to Transform Your Workflow?
Don't miss out on the power of cutting-edge AI.
The Expert AI Terminal USB puts nearly unlimited AI capabilities for your daily professional tasks directly into your hands.
Purchase your Expert AI Terminal USB today and unlock the future of intelligent productivity!